

In the ever-evolving landscape of Generative AI, companies are continually seeking innovative solutions to meet customer demands. One such solution gaining traction is the Retrieval Augmented Generation (RAG) pattern of architecture for Generative AI. Recognizing the increasing need for Vector Store Selection Guidance in this domain, the leading financial services company has successfully implemented a Generative AI application for summarization of documents on AWS with Intel Techworks Engineering team’s specialized skills and today, we’ll delve into their approach.
Vector data stores play a pivotal role in RAG pattern implementations, offering scalability and security necessary for handling vast amounts of domain-specific information. With numerous options available, selecting the right vector data store becomes paramount. Here’s where Intel Techworks Engineering team’s expertise shines, as they’ve navigated through various considerations to make informed decisions.
Key factors which were when choosing a vector data store include:
- Latency of Response
- Level of Product Quantization
- Scale of Vectors to be Stored
- Dimensions of Generated Vectors
- Supported Algorithms (e.g., HNSW, IVF)
- Similarity Metrics Supported
Solution Architecture
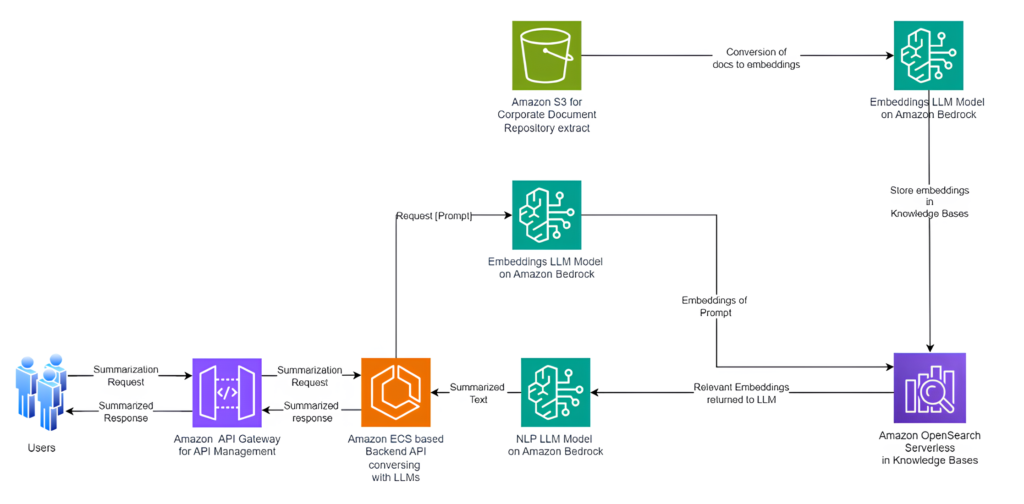
Designing an efficient ingestion pipeline for embeddings, along with prompt and context engineering, are crucial steps in the process. But Intel Techworks has streamlined this process further with the help of AWS’s latest offering, Knowledge Bases (KB) for Amazon Bedrock. At the recently concluded re:Invent 2023, AWS announced the General Availability of KB for Amazon Bedrock, simplifying the evaluation of multiple vector stores.
Here’s a step-by-step guide on how the leading financial services company leveraged KB to set up their vector data store seamlessly:
- You start by naming the Knowledge Base relevant to one of the Business Units to whose data corpus this was being created for.
- Created a Data Source Data source by ingesting data from an S3 location where all the corpus was available.
- The workflow on KB offers a choice between different types of vector stores, including Amazon OpenSearch Serverless (OSS) for new deployments or pointing to existing deployments of OSS, Aurora PostgreSQL, Pinecone, or Redis Enterprise Cloud.
- After reviewing the setup, the Knowledge Base is created, with the vector data store provisioned in a few minutes. Titan Embeddings G1 model converts the knowledge corpus into embeddings and stores them into the vector data store.
With the data sync completed, users could initiate initial testing of the Knowledge Base using the user interface and integrations available with LLMs Claude Models. And just like that, Intel Techworks has set up their vector data store within minutes, ready to integrate with agents and applications using SDKs and APIs provided by AWS.
Conclusion
Intel Techworks’s successful implementation of Generative AI Apps on AWS showcases the power of leveraging innovative technologies to meet customer demands efficiently. By embracing solutions like Knowledge Bases for Amazon Bedrock, companies can accelerate their AI initiatives and stay ahead in today’s competitive landscape. So, whether you’re embarking on your AI journey or looking to enhance existing capabilities, Intel Techworks’s experience serves as a guiding light to help you navigate the complexities of AI implementation on AWS.
Looking to solve a similar problem?
Reach out to us to get started with this transformation –Contact Intel Techworks.